4. ウェブを収集する単位
ウェブアーカイブでは、何らかのまとまり(単位)でウェブサイトを管理します。主なものとしてターゲット単位とページ単位があります。単位を決定するにあたっては、収集の規模、保存したサイトの見せ方、収集の効率性などがポイントとなります。
ターゲット単位
小規模な収集
選択収集の多くは小規模なまとまりで収集するため、機関単位あるいはウェブサイト単位で収集する対象(ターゲット)を設定します。機関単位であれば「国立国会図書館」や「総務省」、ウェブサイト単位であれば「平城遷都1300年祭」や「さっぽろ雪まつり」といった具合です。各単位で検索用のメタデータを作成し、その下に保存日ごとに分けてウェブサイトを管理します。ターゲット単位で管理することで、収集や公開に関する許諾の管理がスムーズに行えるなどのメリットがあります。
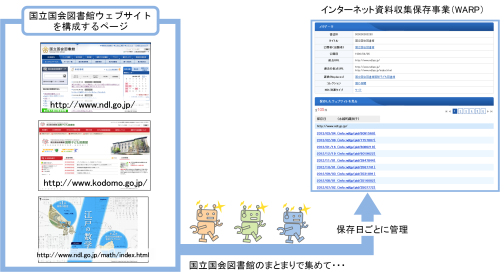
保存したサイトの見せ方
ターゲット単位で保存したウェブサイトの多くは、そのまとまりで公開します。例えばWARPでは、ターゲットのもとに保存日ごとに分けて公開しています。
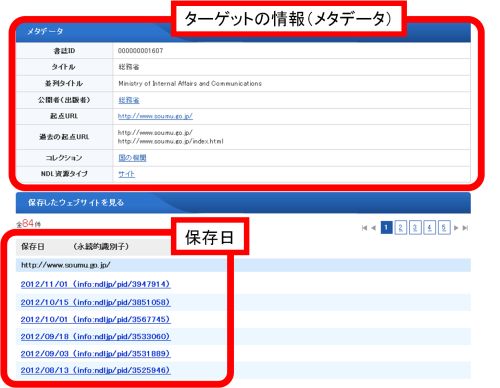
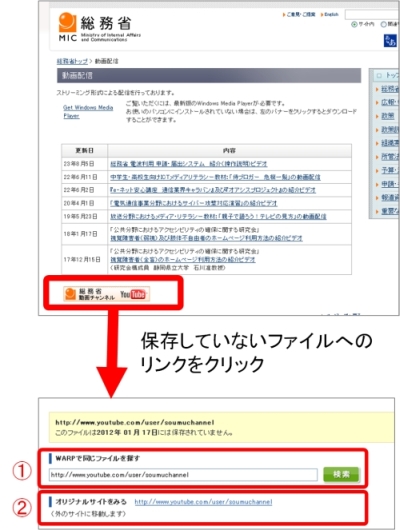
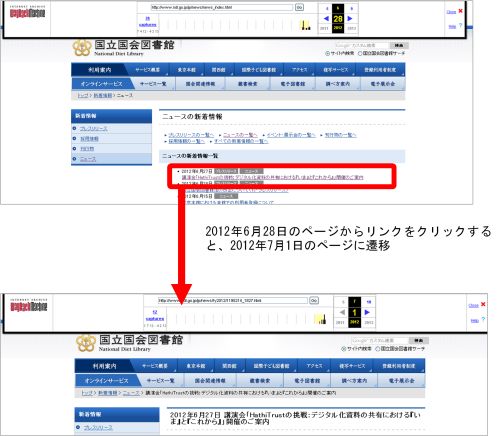
保存したウェブサイトを閲覧している際、リンク先のファイルが同じ日に保存されていない場合には、メッセージ画面が表示されます。他の保存日や、他のターゲットの中に保存されている可能性がありますので、画面に従って検索し直すと見つかる場合があります(①)。また、オリジナルサイトへのリンクもありますので、現在のページへ飛ぶこともできます(②)。
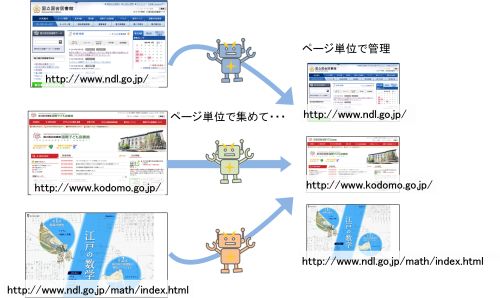
ページ単位
大規模な収集
ページ単位の管理は、バルク収集に多く用いられる方法です。「.fr」や「go.jp」などのドメインレベルで大規模な収集を行い、URLのみで管理します。ターゲット単位とは異なり、検索用のメタデータを付与することはあまりありません。
保存したサイトの見せ方
ページ単位の多くはURLをキーにして検索・閲覧をします。例えばインターネットアーカイブのWayback Machineは、URLで検索をするとカレンダーに保存日が表示されます。

表示されるコンテンツはページ単位で管理されているためターゲットの枠はなく、リンク先のファイルが全体アーカイブデータのなかに保存されていれば表示されます。リンク先のページは、Wayback Machineの場合、保存しているなかで一番近い日付のページが表示されます。
保存したサイトの見せ方においては、ウェブサイトをかたまりとして見るかどうかが、ターゲット単位とページ単位の大きな違いと言えるでしょう。保存日を固定して見せるかどうかは選択事項ですので、システム要件などを考慮して決定します。
収集の効率性
収集ロボットを使用してウェブサイトをクロールする際、同時に走行できる収集ロボットの数(プロセス数)はシステム規模に応じて限りがあります。そのため、1プロセスで複数のURLをまとめて収集すると、より効率よく収集することができます。収集単位を設定する際には、こうした効率性の観点も必要です。
WARPは、ウェブサイトを発信している機関ごとに複数のURLを設定しています。例えば、総務省の場合、総務省のメインサイト(http://www.soumu.go.jp/)のほか、統計局(http://www.stat.go.jp/)、電子政府の総合窓口(http://www.e-gov.go.jp/)を始め十数のURLが存在します。それらを起点(ウェブを収集するしくみ)に設定して、1プロセスで収集を行います。収集したファイルは全体をまとめて「総務省」として管理しています。
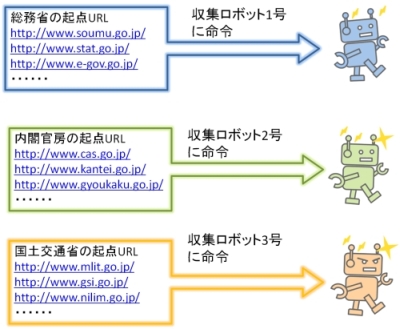
ただし、起点として設定するURLの数が増えるほど1プロセスあたりの収集にかかる時間は長くなるため、プロセス数と起点URL数のバランスを考慮する必要があります。特にバルク収集や大規模な選択収集の場合には、収集する単位と効率性を総合的に勘案した上で収集スケジュールを立てることになります。
WARPでも、同時走行が可能なプロセス数、ターゲット単位での収集保存、公的機関サイトの網羅的収集などを所与条件とし、この条件下で最も効率よく収集ができるように収集スケジュールを設定しています。
(最終更新日:2014/10/1)