7. 収集したウェブサイトの組織化
収集したウェブサイトの組織化について、URL管理、メタデータの付与、全文検索、データマイニングに分けて紹介します。
URL管理
収集したウェブサイトのURLは、オリジナルURLとの関係を保ちつつ、オリジナルURLとは違うものである必要があります。多くのウェブアーカイブでは、日付や識別子とオリジナルURLを組み合わせてURLを付与しています。
日付とURLの組み合わせ
例)http://web.archive.org/web/20040618115539/http://www.meti.go.jp/
2004年6月18日11時55分39秒に収集したhttp://www.meti.go.jp/のページということを表しています。
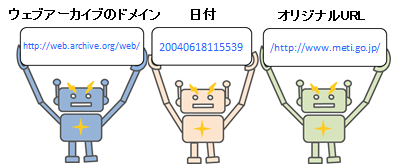
識別子とURLの組み合わせ
例)http://warp.da.ndl.go.jp/info:ndljp/pid/285403/www.meti.go.jp/
保存日ごとに割り振られた識別子(info:ndljp/pid/285403)と、オリジナルURLのhttp://www.meti.go.jp/を組み合わせています。

メタデータの付与
メタデータについては、どのような単位=粒度で付与するかという問題があります。以下の3つの観点から考えてみましょう。
アーカイブの規模
バルク収集の場合、膨大な収集を行うため粒度の細かいメタデータを付与しづらいのに対し、選択収集の場合、収集量は小規模なため、比較的細かいメタデータを付与しやすい傾向があります。
需要と供給のバランス
利用する側が求めるメタデータの粒度に対し、提供する側がそれに対してどこまで応えられるかという視点は重要です。
利用する側が詳細なメタデータを求める場合、提供する側はできる限りその要求に沿った粒度のメタデータを用意するのが理想です。
しかし、ウェブコンテンツの量が膨大であること、人的・財政的制約があることなどから、全てのウェブコンテンツに詳細なメタデータを人的に付与するのは現実的ではありません。
将来的には、セマンティック・ウェブなどの技術を活用して、収集したウェブサイトの内容をシステムが理解し、自動でメタデータを付与することが期待されます。また、ソーシャルタギングのように、閲覧しているコンテンツに対しユーザ自身が主題等のメタデータを付与する仕組みを導入することも考えられます。
対象コンテンツ
対象コンテンツによっても適切な粒度は異なります。
ターゲット単位で収集を行う場合、収集前にターゲットのタイトル・公開者(出版者)・起点URL等のメタデータをターゲットに付与します。このメタデータ、若しくは項目が追加されたメタデータが、そのままウェブサイト閲覧時の検索においても流用されます。効率よく収集ができる単位で付与されているため、粒度は粗くなりがちです。
一方で、精度の高い検索結果が求められるコンテンツに対しては、粒度の細かいメタデータを集中的に付与することもあります。例えば、ウェブアーカイブの多くは国立図書館が実施していますが、図書館としては、電子雑誌の論文記事の単位でメタデータを付与するのが望ましいでしょう。
国立国会図書館では、保存したウェブサイトの中から白書、会議資料、報告書、年報、論文などの刊行物を取り出し、それらに対しメタデータを付与しています。こうすることで、ウェブサイト中に散在する刊行物を効率よく検索・閲覧でき、従来の紙の刊行物との連続的なアクセスも保障されます。これらは国立国会図書館デジタルコレクションから検索・閲覧できます。
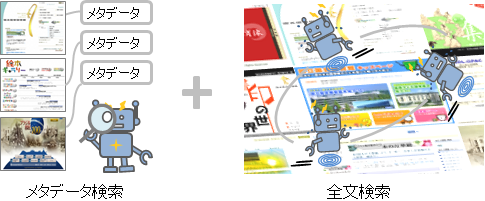
全文検索
メタデータと全文検索の補完関係
検索をする場合、メタデータだけではそれより細かい情報はヒットしません。そこで、全文検索インデクスを作成し、ウェブサイト本文をより細かく検索できるようにします。世界のウェブアーカイブ機関の約6割が、この全文検索の機能を提供しています。[ⅰ]
多くのウェブアーカイブで使われている全文検索エンジン Solrは、検索結果を適合度順に表示することができますが、同時に不要な情報も数多く表示されます。
メタデータによる粗くてノイズの少ない検索と、全文検索による細かくてノイズの多い検索、それぞれの特徴を活かしながら検索サービスを提供することが必要です。
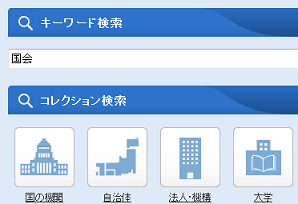
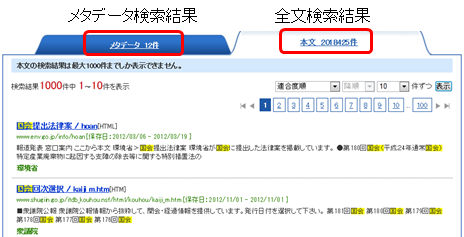
WARPの検索サービス
WARPでは、メタデータ検索と全文検索を組み合わせた検索サービスを提供しています。検索する際は、トップページのキーワード検索欄に単語を入力し検索します。
検索結果画面では、メタデータの検索結果と全文検索の結果が同時に表示され、タブで両者を切り換えることができます。
インデキシングの維持
全文検索サービスを提供するためには、高い全文検索能力を備え、かつ高速なインデキシングが可能な検索サーバが必要です。また、日々保存されるウェブサイトは膨大な数に上るため、それを処理・保存できるリソース・技術も必要です。
データマイニング
収集した膨大なアーカイブデータを解析し、データの相関関係、パターンなどを探し出す技術のことをデータマイニングと言います。ウェブアーカイブ機関でも、様々なデータマイニングの試みが行われています。[ⅱ]
UK Web ArchiveのVisualization(可視化)はその好例で、ある特定の単語がアーカイブ中に出現する頻度を時系列で表示する「N-gram Search」(「世界のウェブアーカイブ」においても解説)や、収集したウェブサイトを収集年ごとに解析し、ファイルフォーマットの流行を分析する「Format Analysis」などがあります。
参考文献
- [ⅰ] Daniel Gomes, Joao Miranda, and Miguel Costa. "A survey on web archiving initiatives"(accessed 2013-10-29).
- [ⅱ] Emily Reynolds. "Web Archiving Use Cases"(accessed 2013-10-29).
(最終更新日:2016/10/19)