Wayback Machine は、インターネットアーカイブ(Internet Archive)が保存しているウェブサイトを閲覧できるサービスです。
インターネットアーカイブは世界中のウェブ情報を代表とするさまざまなデジタル情報をアーカイブしている非営利法人です。1996年にBrewster Kahle氏によって設立されました。
インターネットアーカイブはなぜデジタル情報を集めているのでしょう。それはデジタル形式で保存された歴史資料を、研究者や歴史学者ひいては全世界の人々が将来にわたって利用できるようインターネット上に図書館を作るためです。保存しているデータ量は、40ペタバイト(約4万テラバイト)以上になります(2019年2月現在)。当初、インターネットアーカイブはウェブ情報の保存に力を入れていましたが、現在は、電子書籍や動画、音源などの保存にも取り組んでいます。
Wayback MachineではURLを指定した検索およびキーワード(ホームページへのリンクに使用された単語)による検索が可能です。ウェブページの全文検索機能はありません。
一般的なのはURL検索です。インターネットアーカイブのトップページやWayback Machineのトップページにある検索フォームに閲覧したいウェブページのURLを入力します。
以下のようなカレンダーが表示されます。このカレンダーから日付を選択すればその日のウェブページを閲覧することができます。
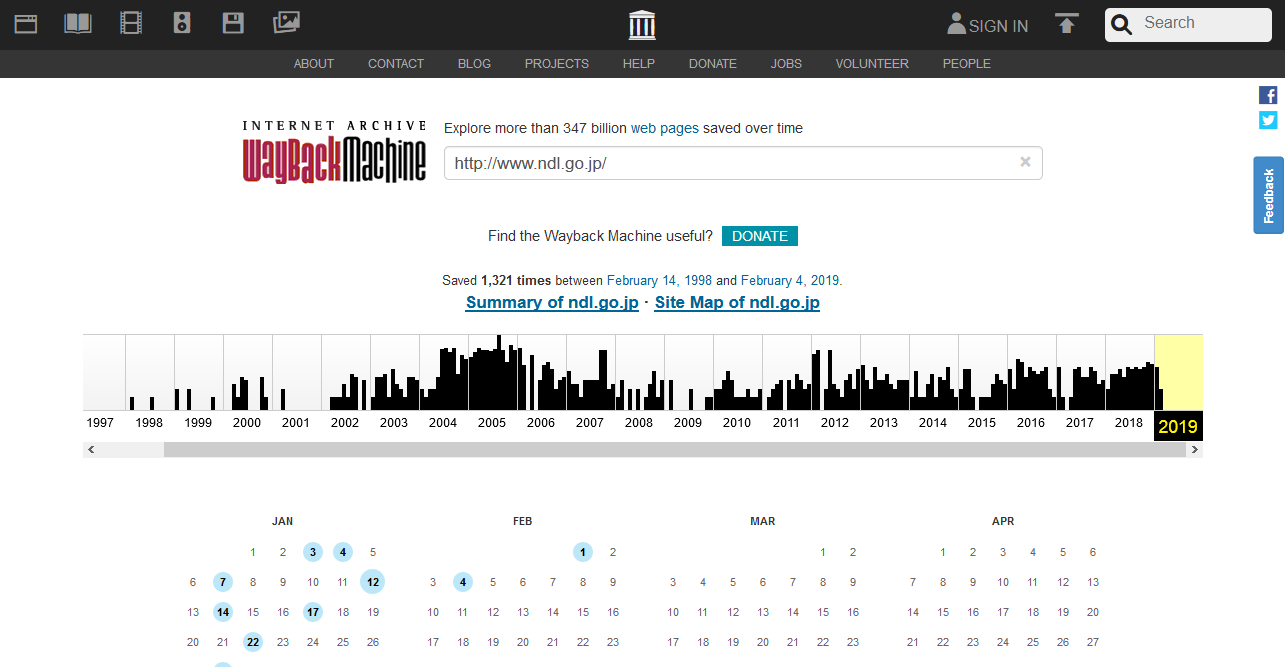 Wayback Machineのカレンダーナビゲーション
Wayback Machineのカレンダーナビゲーション
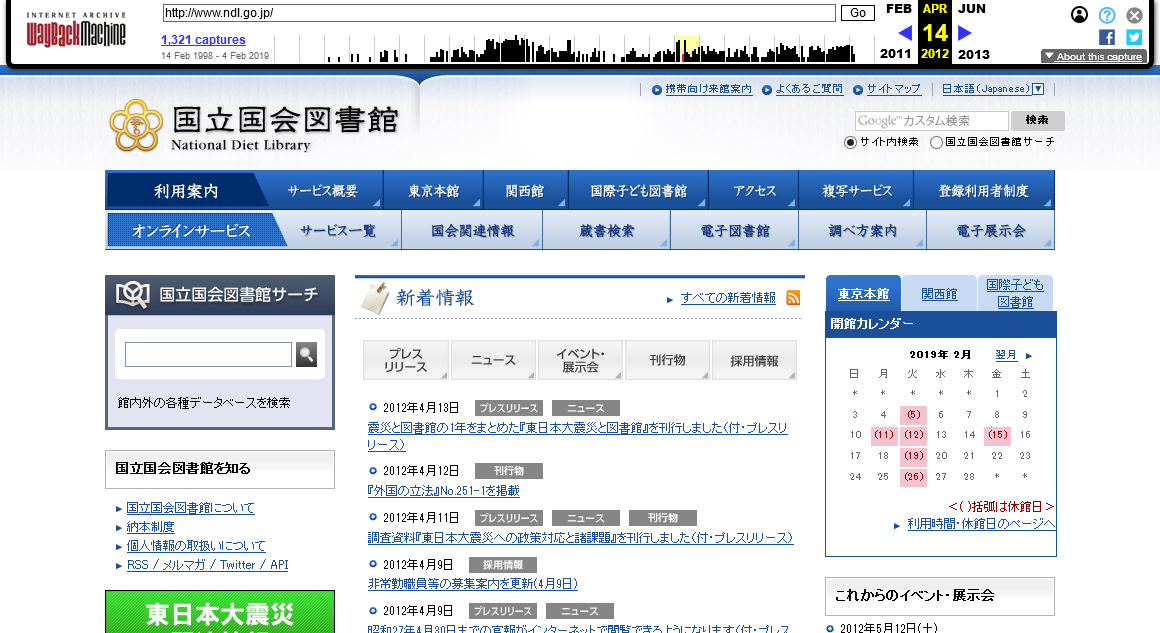
試しに2012年4月14日の国立国会図書館ホームページを見てみましょう。
カレンダーから該当する日を選択すると、URLがhttps://web.archive.org/web/20120414205607/http://www.ndl.go.jp/となるページが表示されます。このURLは2012年4月14日20時56分07秒に収集したhttp://www.ndl.go.jp/のページということを表しています。
画面上部のツールバーで閲覧したい日付を選択すれば、別の日に収集したウェブページを閲覧することができます。閲覧しているページの中にあるリンクから遷移する際は、閲覧しているページの収集日に最も近い日付に収集したページへと遷移します。
キーワード検索は、キーワードに関連したウェブサイトを検索する機能です。ウェブサイトのトップページへのリンクに使用された語句を解析することで実現されています。キーワードを入力すると、関連するウェブサイトの一覧が表示されます。一覧中のURLまたはサムネイル画像をクリックすると、カレンダー表示に移動します。
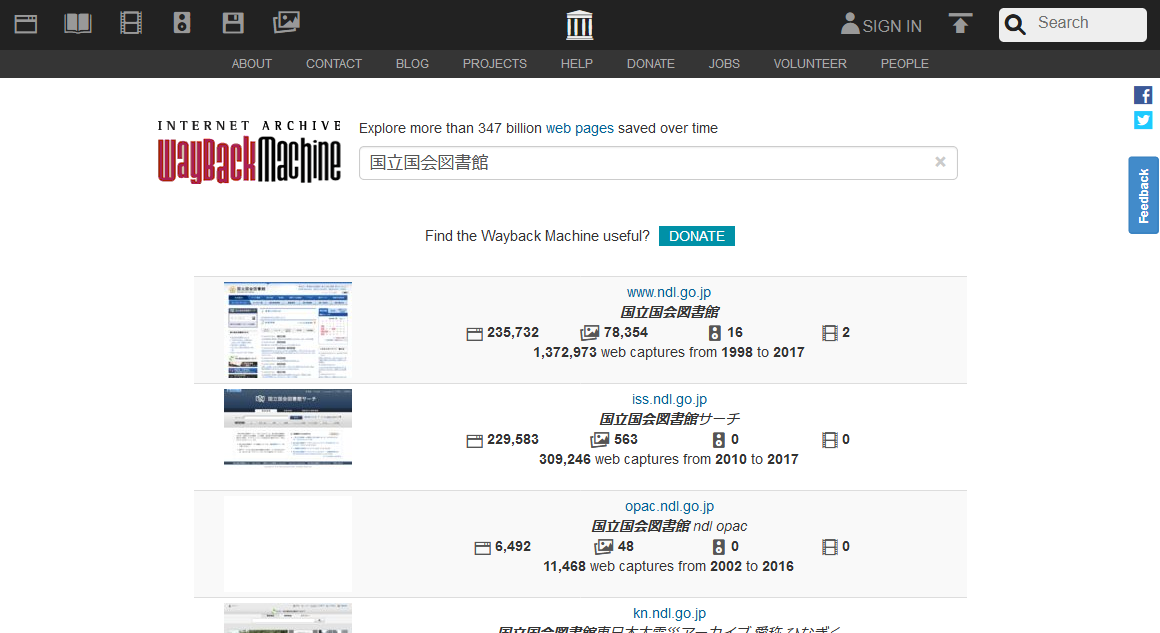 キーワード「国立国会図書館」の検索結果画面
キーワード「国立国会図書館」の検索結果画面
なお、Wayback Machineでウェブサイト中の全てのページが閲覧できるわけではありません。技術的に収集が難しいウェブページなど、収集ロボットが収集できないページがあるからです。もしリンクの遷移先のページが保存されておらず、そのページが現在も存在する場合は、ページの保存を促すリンクが表示され、クリックするとWayback Machineにその時点のページが保存されます。
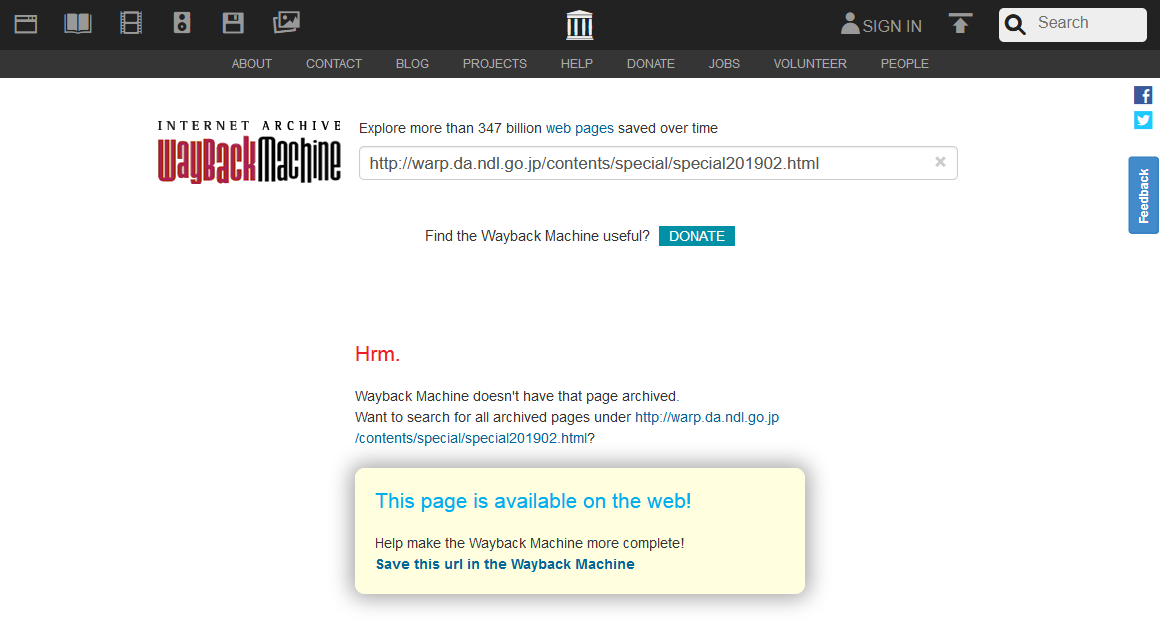 指定されたURLを収集していないというメッセージ
指定されたURLを収集していないというメッセージ
次は、ウェブサイトの収集についてです。インターネット上にあるウェブサイトの数は非常に膨大で、次々に新しいサイトが作られ、また消えていきます。インターネットアーカイブはそれら全てのサイトを収集できているわけではありません。インターネットアーカイブは主要なディレクトリサービスや有名なサイトにはられているリンクから収集対象とするウェブサイトのURL情報を見つけます。もし、ウェブサイトがそれらからリンクされていなければ、そのサイトはインターネットアーカイブに収集されません。また、パスワードで保護されている場合もインターネットアーカイブには収集されません。なおインターネットアーカイブは、保存された自分のウェブサイトや著作権侵害コンテンツをWayback Machineから取り下げてほしいという要求も受け付けています。以下のヘルプページの記載をご覧ください。
もし特定のページを収集してほしい場合は、Wayback Machineのページにある"Save Page Now"から依頼すると、その時点の特定ページが保存されます。 保存されるのはURLで指定したページとその関連ファイル(画像等)のみです。リンクをたどってサイト全体を保存することはしません。
 特定ページの収集を依頼できる"Save Page Now"
特定ページの収集を依頼できる"Save Page Now"
Wayback Machineにはこれまでに3,470億以上のウェブページが保存されています(2019年2月現在)。なお、ウェブページが収集され、Wayback Machineで閲覧できるようになるまでには3時間~10時間かかります。
インターネットアーカイブが運営しているサービスはWayback Machineだけではありません。そのうちのいくつかを紹介します。
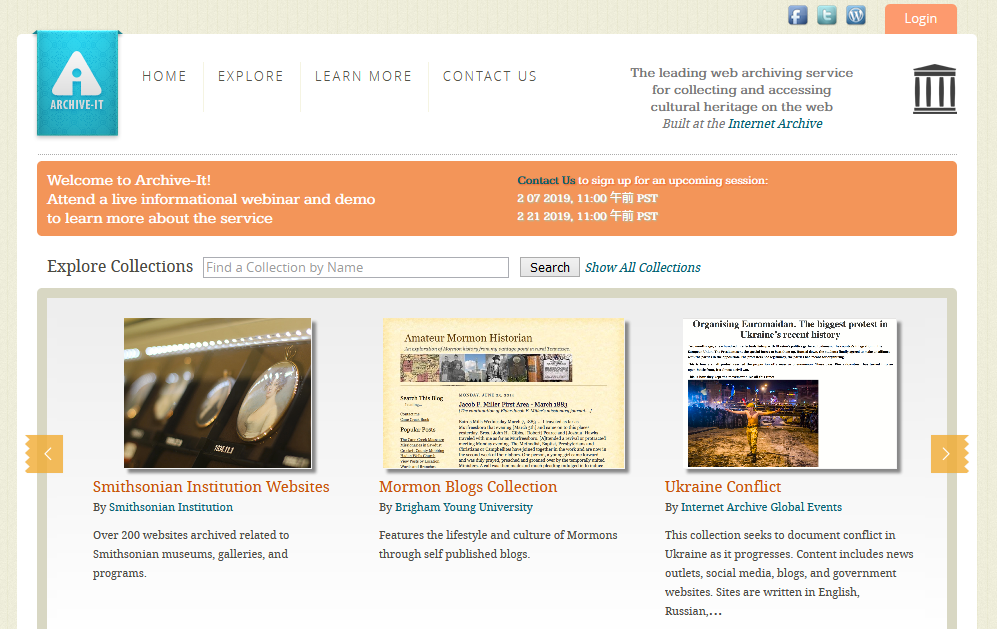
Archive-Itという有料のサービスを提供しています。
ウェブアーカイブの専門知識がなくても、Archive-Itが用意した操作画面を使えば簡単にサービス利用者が指定した組織のウェブサイトを保存することができます。保存したウェブサイトはインターネットアーカイブに保管され、全文検索ができるようになります。
インターネットアーカイブはOpen Libraryというプロジェクトの運営も行っています。
このプロジェクトでは、これまでに出版されたすべての書籍に関する情報を集めようとしています。Open Libraryを使えばインターネットアーカイブに保存されている児童書から学術書までの様々な電子書籍を利用できます。インターネットアーカイブに保存されていない場合もWorldCatやオンライン書店へ遷移することができます。また、インターネットアーカイブでは図書館と協力して書籍のデジタル化も行っています。2011年の9月にはその数が200万冊に達しました。
昔の映画やニュース映像、音楽ライブの音源、オーディオブックなど幅広く動画や音源を集めています。例えば、グレイトフル・デッドのライブ音源やテレビのニュース番組などが保存されています。
(最終更新日:2019/02/15)